本文最后更新于:2024年5月11日 下午
之前注册的jihulab仓库做图床,类似于GitHub,但是偶然登录时提示试用期已经结束,需要购买专业或者旗舰版使用,为了避免保留期结束后数据被清空,所以需要迁移图片,之前买的服务器还是腾讯云的,所以这次选择用腾讯云cos。
配置图床
申请COS
先登录腾讯云,登录后搜索对象存储进入概览页面,新用户进去会送6个月的标准存储包,按照步骤领取后就可以创建存储桶了(如下图)
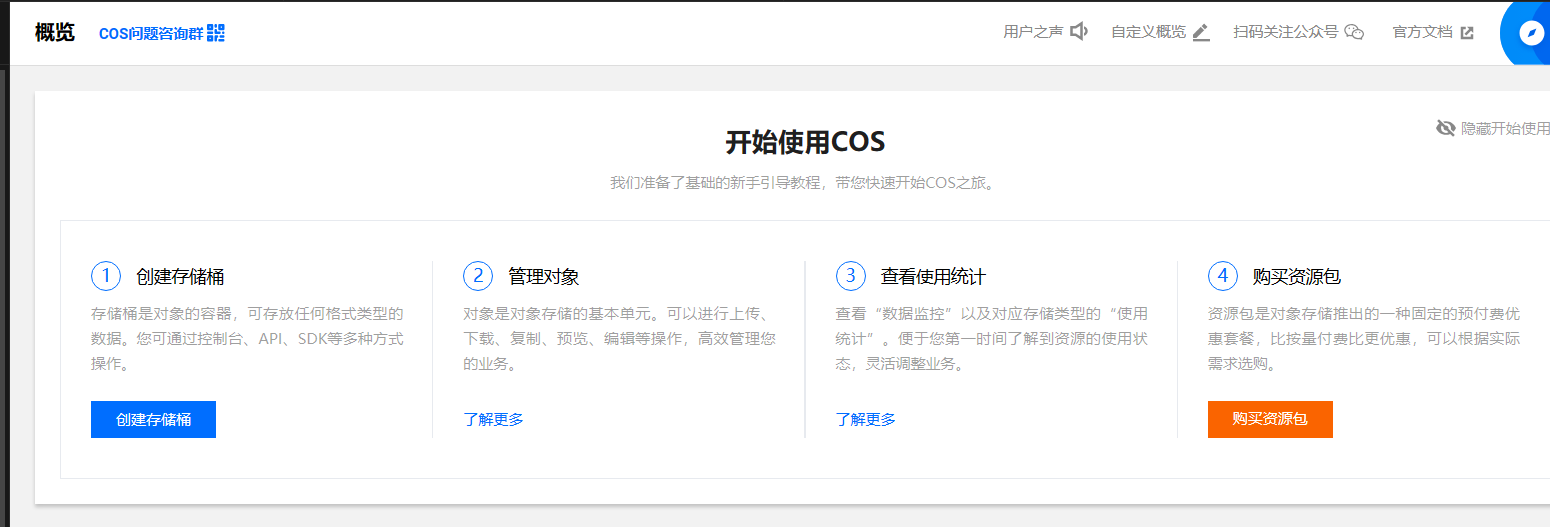
创建一个桶,访问权限设置为公有读私有写,不然图片上传后不能访问,还得配置账号身份验证(安全问题可以通过设置防盗链)

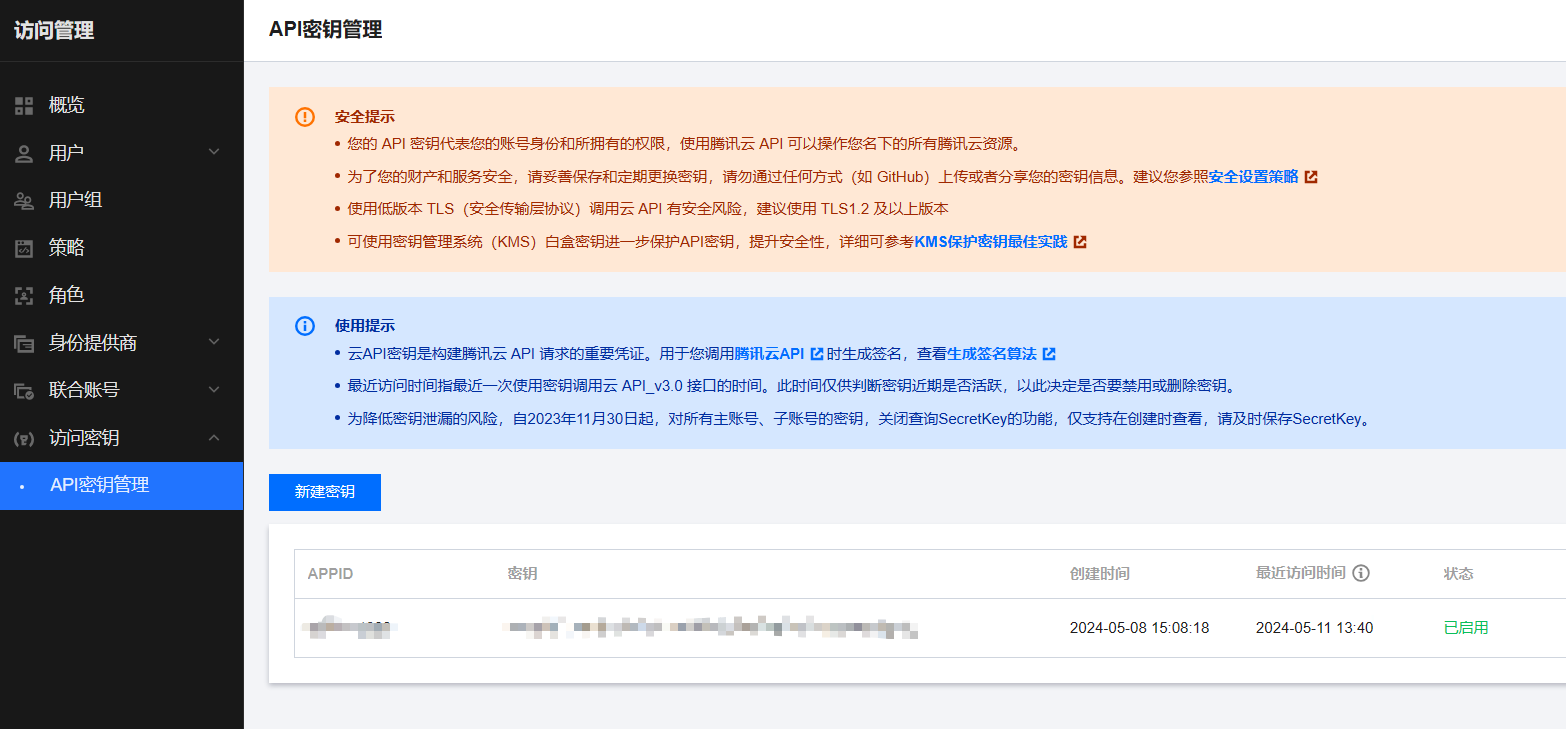
搜索进入 API 密钥管理,创建一个访问密钥
配置PicGo
准备好基本信息后进入picgo,配置腾讯云cos相关参数:

此时就可以正常上传图片使用了
配置域名
默认上传的域名(源站域名)是根据 bucket 名称、地域名称生成的,例如我的是:leslie1-1309334886.cos.ap-shanghai.myqcloud.com,自己有的域名话可以替换一下,存储桶列表点击进入详情,左侧域名与传输管理中添加一条自己的域名,在域名解析里添加CNAME解析即可

在picgo出同样添加以下即可,已经上传的图片引用处正则替换一下就行
腾讯云cos注册送的6个月标准存储容量包,但是流量使用也会产生费用,需要买流量包。
可以考虑又拍云,有免费10G存储和15G流量。操作方式和cos基本一致
图片迁移
之前在 jihulab 上的图片有几百张,手动一张张下载再重新上传太麻烦,刚好发现 PicGo 运行会启动一个本地 Server,根据他的文档是可以利用 api 上传的,写一个简单的代码去做这个工作逻辑:
- 找到文本中 jihulab 的图片;
- 下载图片到指定文件夹;
- 把图片通过 PicGo 上传;
- 替换得到的新 url;
我在完全没有学习过 python 的情况下,简单写一个 py 程序,工具如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
| import os
import re
import urllib.request
import json
import base64
import logging
img_pattern = re.compile(r'https://jihulab\.com/.*\.gif', re.IGNORECASE)
folder_path = 'E:\\python-script\\posts'
image_save_path = 'E:\\python-script\\image_save'
if not os.path.exists(image_save_path):
with open(image_save_path, 'w'):
pass
upload_request = 'http://127.0.0.1:36677/upload'
logging.basicConfig(filename='E:\\python-script\\handle.log', level=logging.INFO, format='%(asctime)s - %(message)s')
"""
读取单个md文件,遍历其中所有旧url,下载上传得到新url并替换
"""
def match_and_save(file_path):
if file_path.endswith('.md'):
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
matched_urls = img_pattern.findall(content)
logging.info("开始处理: {}".format(file_path))
for url in matched_urls:
logging.info("\t>>>>原始URL: {}".format(url))
img_name = os.path.basename(url)
img_abPath = os.path.join(image_save_path, img_name)
urllib.request.urlretrieve(url, img_abPath)
logging.info("\t\t本地图片路径: {}".format(img_abPath))
data = {
'list': [img_abPath]
}
req = urllib.request.Request(upload_request, json.dumps(data).encode('utf-8'), {'Content-Type': 'application/json; charset=utf-8'})
with urllib.request.urlopen(req) as response:
res = json.loads(response.read().decode('utf-8'))
logging.info("\t\t响应体:{}".format(res))
if res['success']:
new_url = res['result'][0]
content = content.replace(url, new_url)
with open(file_path, 'w', encoding='utf-8') as f:
f.write(content)
for file_name in os.listdir(image_save_path):
file_path = os.path.join(image_save_path, file_name)
if os.path.isfile(file_path):
os.remove(file_path)
logging.info("处理完成: {}\n".format(file_path))
return []
"""
文件则调用方法,文件夹则递归遍历
"""
def traverse_folder(folder_path):
if os.path.isdir(folder_path):
for item in os.listdir(folder_path):
item_path = os.path.join(folder_path, item)
traverse_folder(item_path)
elif os.path.isfile(folder_path):
match_and_save(folder_path)
traverse_folder(folder_path)
|
代码都是 ctrl + i 快捷键问 GPT 生成的,我只是每个逐个方法校验一遍,调整生成的代码即可