本文最后更新于:2024年4月16日 下午
消息应答
1、问题引出
假设消费者处理某个业务功能需要100条消息,现在获取了50条,还没处理完进程就终止了。
按照入门示例写的代码,未处理的消息就会被直接丢弃,而剩余未发送的50条消息,也不会再发给它了,因为它是不可接收的状态了。即此时这100条消息还未实现对应功能便被丢失了!
2、解决方案
为了保证消息能可靠的到达消费者并处理,RabbitMQ引入了消息应答机制(message acknowledgement)——消费者在接收并且处理该消息之后,告诉 rabbitmq 它已经处理了,rabbitmq 可以把该消息删除了。
如果某个消费者处理时异常结束没有发送应答,RabbitMQ就会认为这条消息没被处理,然后交给另外一个消费者。这样就可以保证即使消费者挂掉也不会丢失消息数据
自动应答
入门示例中消费者采用的是自动应答——即消息发送后就被认为发送成功。
1
2
| boolean autoAck = true;
channel.basicConsume(QUEUE_NAME, autoAck, consumer);
|
自动应答模式需要在高吞吐量和数据传输安全性方面做权衡,
- 自动应答没有对传递消息的数量做限制,可以实现消费者接收过载的消息
- 但是有可能会使得消费者端产生消息的积压,导致内存耗尽,消费者进程被系统杀死
- 而且在消息接收处理完之前,消费者出现问题,那么消息就会丢失
所以自动应答,应该是在消费者可以高效并以 某种速率能够处理这些消息的情况下使用
手动应答
手动应答即关闭自动应答,在回调逻辑中进行手动处理应答
1
2
| boolean autoAck = false;
channel.basicConsume(QUEUE_NAME, autoAck, consumer);
|
手动应答有几个实现方法:
Channel.basicAck:用于消息的肯定确认,表示已接收并处理该消息了,MQ可以删除它了Channel.basicNack :用于消息的否定确认Channel.basicReject:用于消息的否定确认,比basicNack少一个参数,如果队列未配置死信队列则直接丢弃,有配置则发送到对应死信队列中
确认应答
1、编写代码
生产者代码保持入门DEMO不动,调整消费者的消费成功回调逻辑即可
这里是AckConsumer1的处理,AckConsumer2只需要调整延时1秒即可,模拟不同业务的处理时间
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| public class AckConsumer1 {
private static final String QUEUE_NAME = "ack_queue";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
System.out.println("开始消费");
try {
System.out.println("模拟实际业务操作,耗时20秒");
TimeUnit.SECONDS.sleep(20);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("接收到消息:" + new String(delivery.getBody()));
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
};
CancelCallback cancelCallback = (consumerTag) -> {
System.out.println(consumerTag + "--->消费者取消了消费接口");
};
System.out.println("Work02 等待消费消息........");
channel.basicConsume(QUEUE_NAME, false, deliverCallback, cancelCallback);
}
}
|
2、测试
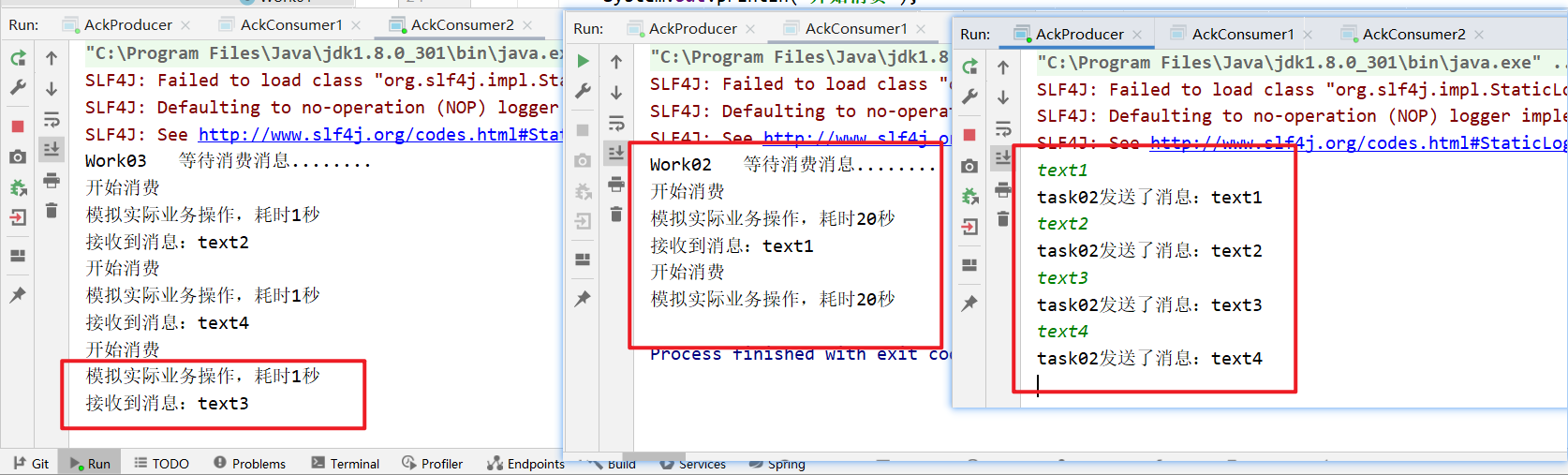
- 消费者发送了4条消息,按照默认的轮询逻辑,text1、text3会被
AckConsumer1消费,text2、text4会被AckConsumer2消费
- 其中
AckConsumer1处理并应答的时间较长,中途挂掉了后,未处理的text3消息会重新入队被AckConsumer2消费
通过管理面板也可以看到队列中消息的状态

否定应答
否定应答代码与确认应答类似,只是调用方法由basicAck变成basicNack或者basicReject
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
DeliverCallback deliverCallback = (consumerTag, message) -> {
System.out.println("消费者A对消息进行消费!");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("消费者A接收到的信息为:"+new String(message.getBody()));
channel.basicNack(message.getEnvelope().getDeliveryTag(),false, false);
channel.basicReject(message.getEnvelope().getDeliveryTag(),false);
};
|
持久化
持久化分为三个部分:交换器持久化、队列持久化、消息持久化
其中如果交换器不设置持久化,mq重启后并不会丢失消息,丢失的是该交换器的元数据,只是之后不能将消息发送到该交换机了,对于常用的交换机建议将其持久化。交换器的持久化在声明方法exchangeDeclare中设置durable参数为true即可
上面的消息应答,作用是避免消费者出现事故时消息丢失,而如果要避免RabbitMQ出现事故导致的消息丢失,则需要将队列和消息标记为持久化的
队列持久化
之前声明队列的第二个参数durable默认都是false,即非持久化的,rabbitmq如果重启就会删改该队列,将参数设置为true后可以保证队列不被删除
1
2
3
4
|
boolean durable = true;
channel.queueDeclare(TASK_QUEUE_NAME, durable, false, false, null);
|
在生产者声明队列时设置持久化参数后,可以在管理面板中查看

【注】如果之前创建队列dur_queue非持久化,再创建持久化,会报错参数不等价,反之亦然

消息持久化
队列持久化只能保证rabbitmq下线时不会删除队列,但是队列中的消息如果要不丢失,也需要开启持久化!通过生产者发布消息时第三个参数BasicProperties添加MessageProperties.PERSISTENT_TEXT_PLAIN来实现
可以将所有消息都设置持久化,但是会影响RabbitMQ性能,因为磁盘的读写速度远慢于内存读写!对于可靠性不高的消息可以不采取持久化。对于消息持久化的选择需要综合可靠性和吞吐量
1
2
|
channel.basicPublish("", QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN, msg.getBytes());
|
将队列、消息都设置为持久化后,就能百分百保证消息不丢失了吗?当然是不行的!
- 如果消费者设置自动应答,应答后没处理就宕机了,那应答的消息肯定就丢失了。这一部分可以通过手动应答处理
- RabbitMQ并不会每次遇到一条持久化的消息都(调用内核的fsync)进行同步存盘操作,而是会先保存到操作系统的缓存中再存入磁盘,这个时间间隔很短但是存在!如果在这个间隔内发生宕机还是会丢失消息
因此队列+消息持久化设置持久性保证不强,只能用于一些简单场景,可以采用的参考方案是**MQ集群+发布确认+消息缓存Redis(AOF备份)**来保证消息不丢失
消息优先级
消息队列默认是先进先出的,消费顺序也是如此,如果需要使后面的某些特定消息先进行消费,需要对队列和消息设置优先级
设置了优先级的队列和消息,会在队列中排序。没有设置优先级的消息依旧按照进入队列的顺序消费,消费者需要在消息进入队列排序完成后消费才能体现优先级。优先级范围为 0~255,值越高优先级越高,且消息优先级不能超过队列优先级
1、生产者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| public class PriorityProducer {
public static final String EXCHANGE_NAME = "FanoutExchange";
public static void main(String[] args) throws Exception {
final Channel channel = RabbitMQUtils.getChannel();
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.FANOUT);
HashMap<String, Object> map = new HashMap<>(1);
map.put("x-max-priority", 10);
channel.queueDeclare("PriorityQueue", false, false, false, map);
channel.queueBind("PriorityQueue", EXCHANGE_NAME, "", null);
for (int i = 0; i < 10; i++) {
String msg = "INFO_" + i;
if (i % 3 == 0) {
final AMQP.BasicProperties properties = new AMQP.BasicProperties().builder().priority(5).build();
channel.basicPublish(EXCHANGE_NAME, "", properties, msg.getBytes());
} else {
channel.basicPublish(EXCHANGE_NAME, "", null, msg.getBytes());
}
}
System.out.println("-----消息发送完毕-----");
}
}
|
2、消费者
1
2
3
4
5
6
7
8
9
10
11
12
13
| public class PriorityConsumer {
public static final String QUEUE_NAME = "PriorityQueue";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
DeliverCallback deliverCallback = (consumerTag, msg) -> {
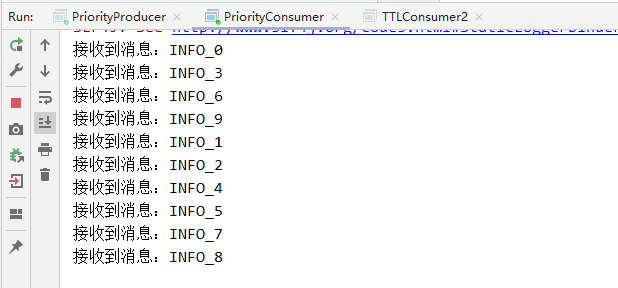
System.out.println("接收到消息:" + new String(msg.getBody()));
channel.basicAck(msg.getEnvelope().getDeliveryTag(), false);
};
channel.basicConsume(QUEUE_NAME, false, deliverCallback, consumer -> {});
}
}
|
可以看到对3取余为0的消息0、3、6、9被提前消费了