1、RabbitMQ快速入门
本文最后更新于:2024年4月16日 下午
1、消息队列
1.1 消息队列的基本概念
消息(Message)是指在应用层之间传递的数据,比如文本字符串、JSON。现在的互联网系统中,前后端各个组件模块间传递数据信息,都可以称之为消息
而消息队列中间件(Message Queue Middleware,简称MQ)则是利用 可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过消息模型,它可以在分布式环境下扩展进程间的通信。
基于此,消息队列有两种模型:
点对点模式(P2P,Point to Point),也可以称作队列模型。基本组成生产者Producer、队列Queue、消费者Consumer,生产者发送消息到队列、消费者从队列中消费消息,总体是一个发->存->收的流程;其中一个队列可以存储多个生产者的消息、一个队列也可以有多个消费者,但是消费者之间对于消息的消费是竞争的,即消息只能被一个消费者消费。

发布订阅模型(P/S,Pub/Sub),发布订阅模型中基本组成为生产者Publisher、主题Topic、订阅者Subscriber
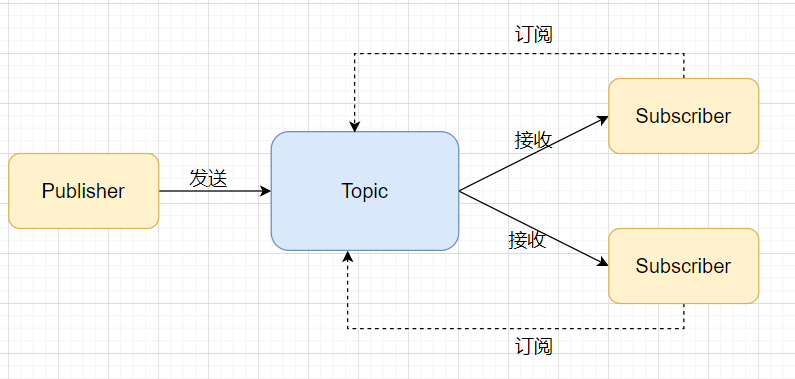
消息中间件适用于需要可靠的数据传送的分布式环境。发送者将消息发送给消息服务器,消息服务器将 消息存放在若干队列中,在合适的时候再将消息 转发给接收者。实现应用程序之间的协同,优点在于能够在客户和服务器之间提供同步和异步的链接,并且在任何时刻都可以将消息进行传送或存储转发。
1.2 为什么用消息队列
消息队列的主要应用场景有三点:解耦、异步、削峰
- 解耦:在引入消息队列之前,上游业务模块A的功能FA可能需要调用到BCD的服务,还需要考虑到怎么调?变更怎么处理?等等。而引入消息队列后,功能FA执行后将消息发送到消息队列,下游的服务需要就自己消费消息即可
- 异步:一个功能的调用链路往往涉及到多个服务,如果调用链路过长,就会导致功能的响应时间过长。引入消息队列后处理异步进行,可以极大降低响应时间
- 削峰:在高峰期大量数据涌入,可能会超出系统能处理的极限,如果有消息队列做缓冲就不至于导致系统宕机
由以上三点可以知道,在个人或小型的系统中其实是不需要消息队列的,消息队列应该主要应用于大型的分布式系统中,以实现系统功能解耦、提高响应率、保证高并发环境的稳定性。
1.3 主流消息队列的简单对比
市场上主流的消息队列有以下几种,他们各有优劣
1、RabbitMQ:使用Erlang语言,基于AMQP(高级消息队列协议)实现的开源消息中间件。消息延迟能做到微秒级,有较好的并发特性,能实现万级流量吞吐
2、Kafka:主要应用于大数据的消息中间件,以超高的并发吞吐量而闻名。能做到十万级的吞吐,毫秒级的延迟,在大数据实时计算和日志采集领域被大规模使用
3、ActiveMQ:作为老牌MQ,基于主从架构实现高可用,能保证较低的消息丢失率
4、RocketMQ:阿里开源的消息中间件。性能好延迟低,有对应的中文社区
如图公众号博主【三分恶】在他的:面渣逆袭:RocketMQ二十三问 中做出了详细对比:

2、RabbitMQ简介
2.1 RabbitMQ概念
RabbitMQ是Erlang基于AMQP(Advanced Message Queuing Protocol)的实现,最初起源于金融系统,用于在分布式系统中存储转发消息
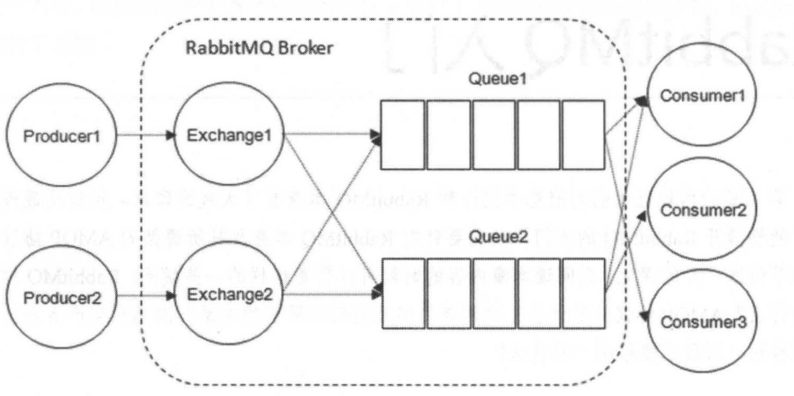
RabbitMQ核心组件
- Producer:消息生产者,投递消息的一方,属于Client;消息一般由两部分组成——标签(label)和消息体(payload)
- Consumer:消息消费者,接收消息的一方,属于Client;消费者连接到RabbitMQ服务器,并订阅到队列上,消费消息时只消费消息体,丢弃标签
- Broker:消息队列服务进程,一般可以将一个Broker看作一台服务器
- Exchange:消息队列交换机,实际上消息并不是由生产者直接投递到消息队列,而是发到交换机Exchange上,由交换机采用相应策略将消息路由转发到对应队列中
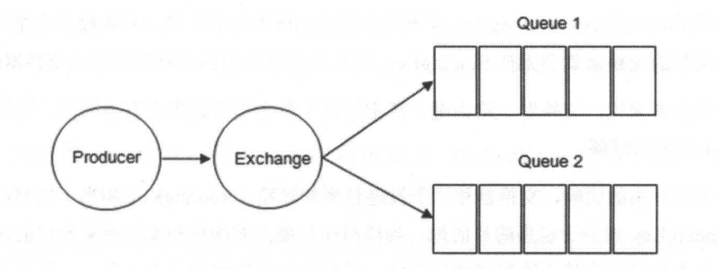
- Queue:消息队列,存储消息的队列,RabbitMQ中消息只能存储在队列中。多个消费者可以订阅同一个队列,此时消息会采用轮询机制(Round-Robin),即消息被平摊给多个消费者,而不是所有消费者都收到所有消息
【注】RabbitMQ不支持队列层面的广播消息,要实现广播需要二次开发,但不建议这么做
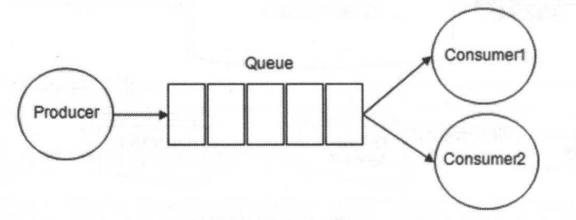
RabbitMQ的运行流程
- 生产者连接到Broker,建立连接(connection)开启信道(channel)
- 生产者声明一个交换机(Exchange),并设置对应属性,如交换机类型、是否持久化等
- 生产者声明一个队列(Queue)并设置对应属性,如是否持久化、是否排他、是否自动删除等
- 生产者通过路由键(RoutingKey)将交换机和队列设置绑定(Binding)
- 生产者发送消息到Broker中,消息包含了路由键、交换器等信息
- 交换机根据设置的类型规则,通过路由键匹配对应的队列
- 如果找到则存入相应的队列中并,可以设置是否确认
- 如果没有找到,则根据之前配置的属性选择丢弃或者回退
- 关闭信道与连接
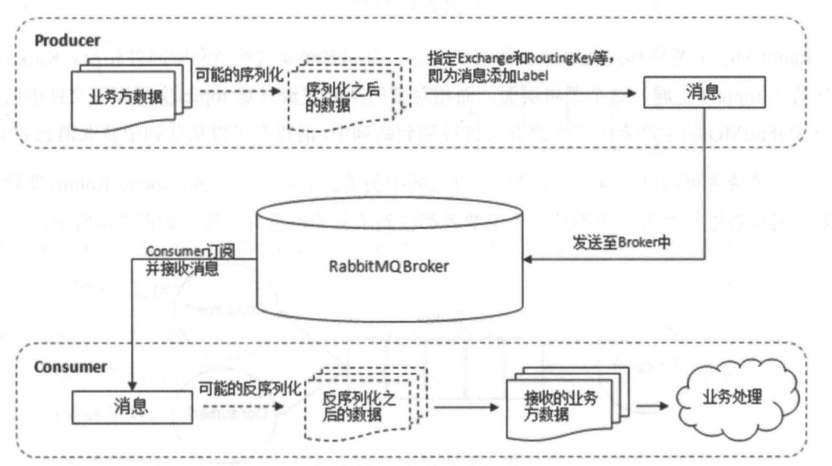
RabbitMQ主要特点
- 可靠性:支持持久化,传输确认,发布确认等保证了MQ的可靠性
- 灵活的分发消息策略:在消息进入MQ队列前由Exchange(交换机)进行路由消息,RabbitMQ提供了内置的Exchange,也可以通过插件自定义
- 支持集群:多台RabbitMQ服务器可以组成一个集群,形成一个逻辑Broker
- 多种协议:RabbitMQ支持除原生AMQP外的多种消息队列协议,如 STOMP、MQTT 等
- 多种语言客户端:RabbitMQ几乎支持所有常用语言,如 Java、Python、Ruby 等
- 可视化管理界面:RabbitMQ提供了一个易用的用户界面,使得用户可以监控和管理消息 Broker
- 插件机制:RabbitMQ提供了许多插件,也可以自定义插件
3、RabbitMQ安装
3.1 安装&运行
Windows安装RabbitMQ需要前置erlang环境
- 在erlang官网下载,
- RabbitMQ的官方下载链接下载
- 下载按步骤安装完毕后,打开RabbitMQ安装目录下的sbin目录,通过命令行界面执行:rabbitmq-plugins enable rabbitmq_management安装管理功能插件
- 执行bat文件即可启动
Linux安装可以参照Windows,也可以使用Docker简化安装操作
指令dockers search rabbitmq搜索相关镜像
由于rabbitmq默认镜像是不带web管理端的,所以可以拉取management后缀的镜像,通过指令docker pull rabbitmq:3.8-management拉取
指令docker run –name rabbitmq -d -p 15672:15672 -p 5672:5672 镜像ID启动镜像

- 其中5672为rabbitmq的通信端口,而15672是web管理页面端口
- 通过docker ps查看正在运行的容器
启动运行后,放行对应防火墙端口才可以访问。firewall-cmd –zone=public –add-port=5672/tcp –permanent开放对应端口,就可以正常访问了,浏览器中键入:虚拟机IP:15672,默认账户密码都是guest,登录
【注】有时强制关闭虚拟机再重启恢复后,会还原虚拟机之前的状态,可以看到docker容器已经在运行,但是对应服务无法访问,通过systemctl restart docker.service就可以访问了
3.2 RabbitMQ的基本使用
命令行与控制台
通过Docker的docker exec -it rabbitMQ容器ID bash进入bash界面,在此处可以通过rabbitMQ自己的命令行进行相关操作。基本命令都是rabbitmqctl xxx形式,详细指令可以参考官方文档:https://www.rabbitmq.com/rabbitmqctl.8.html
1、查看基本信息
1 | |
2、rabbitmq用户操作
1 | |
由于默认的guest 账户有访问限制,默认只能通过本地网络(如 localhost) 访问,远程网络访问受限,所以在使用时我们一般另外添加用户,例如我们添加一个root用户
①执行docker exec -i -t 3ae bin/bash进入到rabbitMq容器内部

②执行 rabbitmqctl add_user root 123456 添加用户,用户名为root,密码为123456

③执行abbitmqctl set_permissions -p / root ".*" ".*" ".*"赋予root用户所有权限

④执行rabbitmqctl set_user_tags root administrator赋予root用户administrator角色

⑤执行rabbitmqctl list_users 查看所有用户即可看到root用户已经添加成功
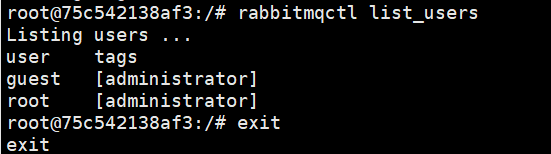
⑥后续可以用root用户登录
3、虚拟主机vhost操作
1 | |
上述操作也可以在管理界面执行,同时管理界面还支持配置文件的导入导出
4、代码测试
4.1 Hello World模型
一个最简单的消息队列就是producer、message queue、consumer,现在Docker部署了队列服务,可以简单写一下生产者消费者

准备pom依赖
1 | |
生产者代码
产生消息的步骤
- 生产者连接到MQ的Broker,创建connection,开启channel
- 生命队列的相关属性:名称、是否持久化、消费模式等
- 发送消息,并指定持久化和routing key等属性
1 | |
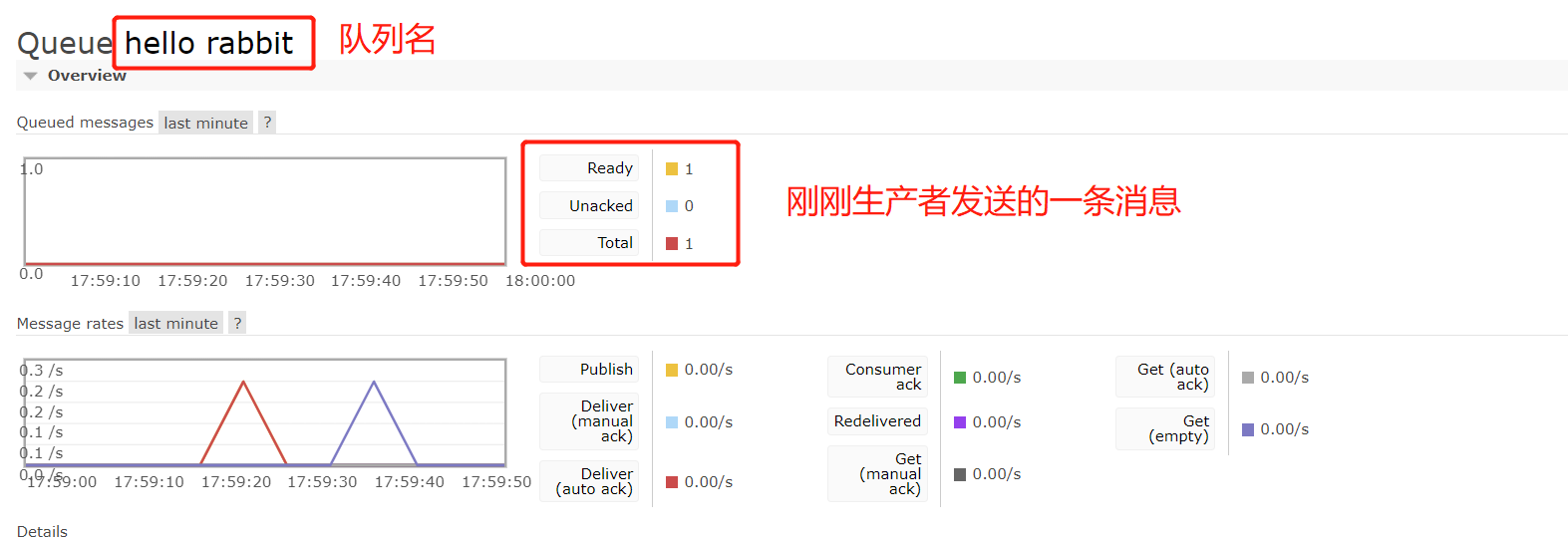
【注】如果先启动消费者,由于MQ里没有相应队列,连接会报错,要先启动生产者发送一条消息到队列中,此时可以看到MQ中创建了队列并有一条消息待消费
消费者代码
1 | |
4.2 Work queue模型
①抽取出创建连接开启通道的代码,得到工具类RabbitMQUtils
1 | |
②创建消费者类Worker01,模拟多个消费者
1 | |
由于多个消费者逻辑代码一样,没必要再去新建类copy代码,直接在IDEA的Run Configuration勾选允许多个实例运行:
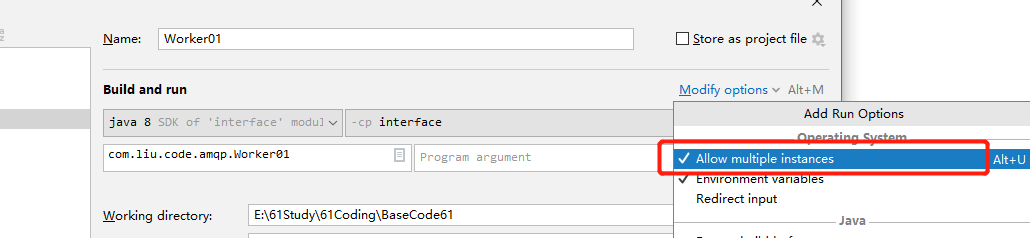
运行Worker01后,修改提示信息为"线程2启动 等待消费消息........",再次Run,得到两个不同的线程
③修改创建者类,使得可以从控制台不断输入
1 | |
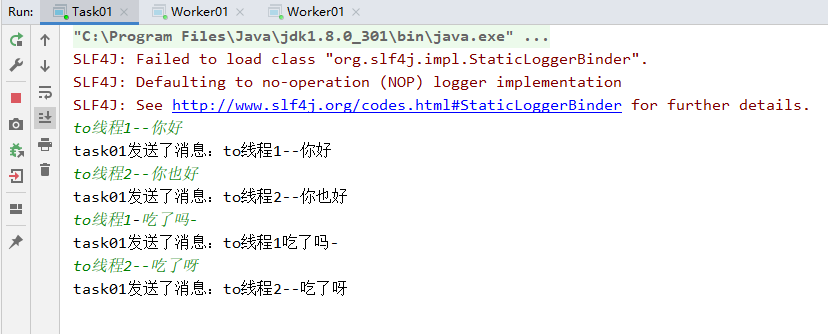
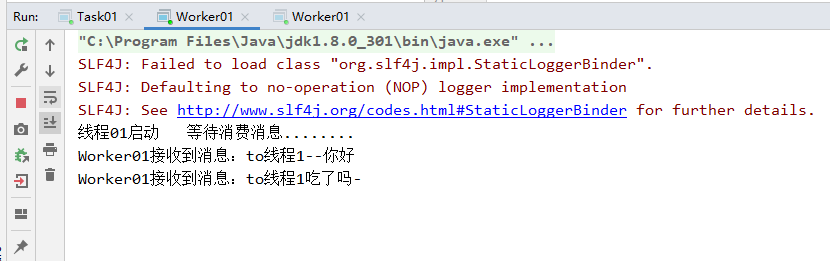
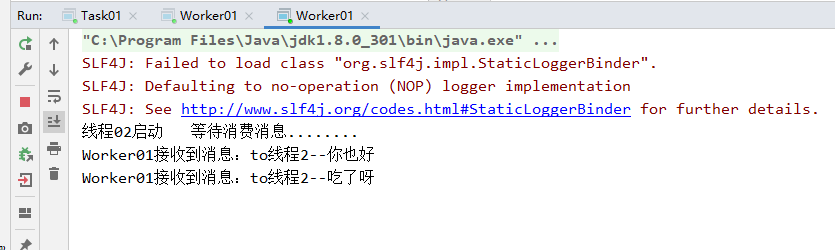
④将三者都启动,输入多条数据,可以发现rabbitmq默认采取轮询策略读取消息
参考
学习主要看的尚硅谷网课,参考评论区两位学员的笔记,以及官方文档和《RabbitMQ实战指南》电子书