Redis学习二:基本数据类型及操作
本文最后更新于:2024年5月11日 上午
Redis简介
Redis是什么
Redis:Remote Dictionary Server(远程字典服务器)是一个开源免费的,用ANSI C语言编写的,遵守BSD协议的高性能(Key-Value)分布式内存数据库,基于内存运行,并支持持久化的NoSQL。
Redis能干嘛
redis是一种支持key-value等多种数据结构的存储系统,有点类似于Java的Map<key,Object>结构。可用于缓存,事件发布或订阅,高速队列等场景。
- 缓存:Redis最主要的用法,能有效提升系统性能
- 排行榜:传统关系型数据库做排行很麻烦,Redis的ZSet很方便
- 计算器/限速器:利用Redis中原子性的自增操作,同级用户的点赞、访问等数据,这类频繁读写的操作采用MySQL会对数据库带来很大的压力;限速器使用的典型场景为限制用户访问某个API的频率,比如出现抢购时,用户点击过多会限制访问,这样可以降低系统压力(限速器也是一种请求限流的实现方式)
- 好友关系:利用Redis的集合特点,通过求交集、并集、差集等获取共同爱好、共同好友等
- 简单消息队列:除了Redis自身的发布/订阅模式,我们也可以利用List来实现一个队列机制,比如:到货通知、邮件发送之类的需求,不需要高可靠,但是会带来非常大的DB压力,完全可以用List来完成异步解耦
- Session共享:默认Session是保存在服务器的文件中,即当前服务器,如果是集群服务,同一个用户过来可能落在不同机器上,这就会导致用户频繁登陆;采用Redis保存Session后,无论用户落在那台机器上都能够获取到对应的Session信息
安装测试Redis
安装Redis
网课给的安装包执行解压报错,因此自行安装。
使用
wget http://download.redis.io/releases/redis-6.2.1.tar.gz获取对应压缩包。使用
tar -zxvf redis-6.2.1.tar.gz解压,得到redis-6.2.1文件夹。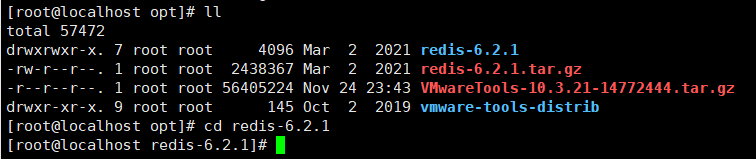
使用
cd redis-6.2.1进入安装目录,执行make指令编译。初次安装的虚拟机执行make会报错。是因为缺少GCC
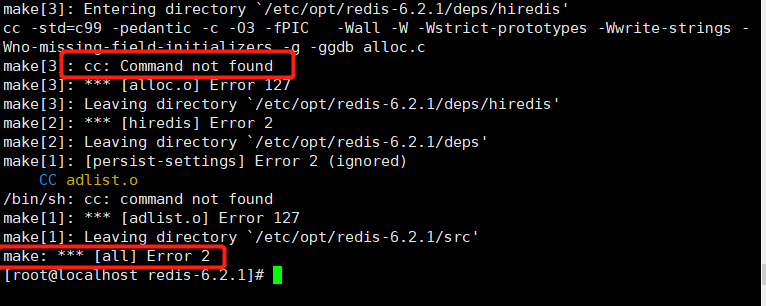
使用
yum install gcc-c++指令安装GCC。报错:Jemalloc/jemalloc.h:没有这个文件或目录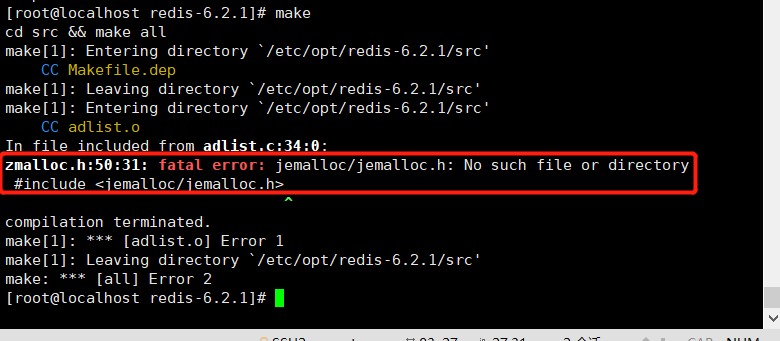
使用
make distclean后再次make即可。
执行make后执行
make install安装。默认安装在
usr/local/bin目录下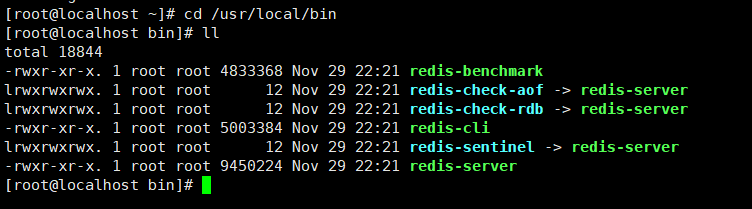
启动测试一下
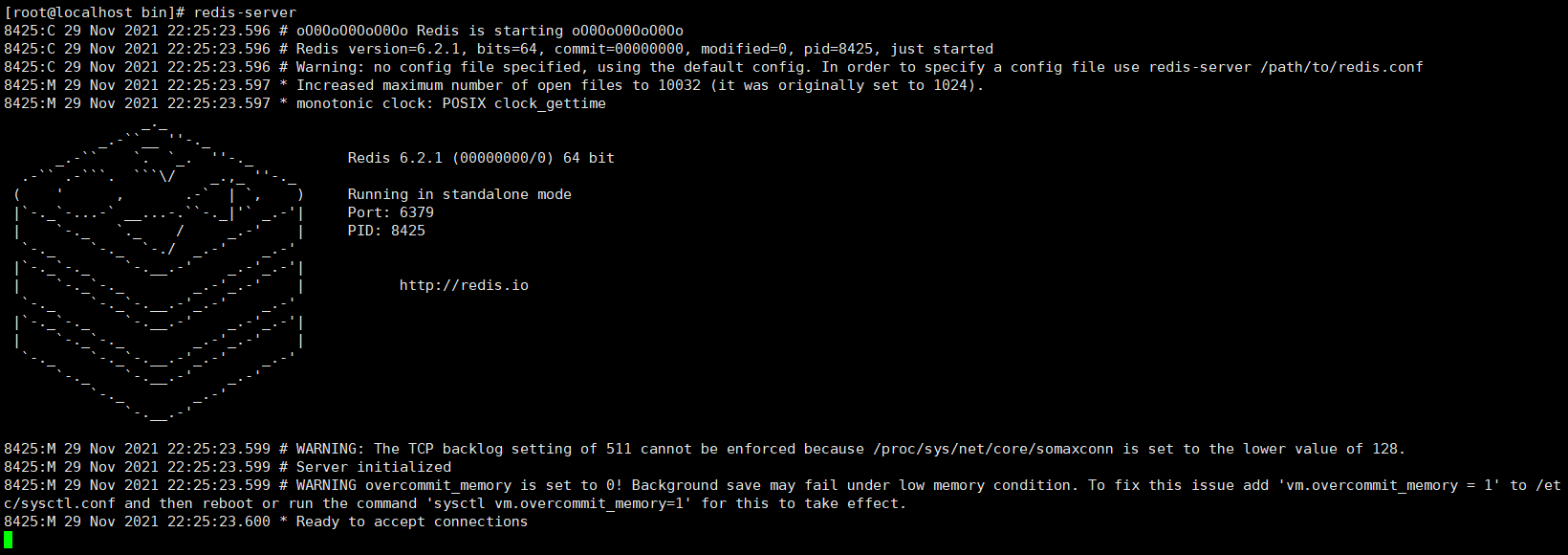
说明
以上说明redis安装成功,不过还有一些需要修改的地方:比如刚才在etc/opt/redis-6.2.1目录下有个Redis.conf文件,这是Redis的配置文件,redis启动时默认按照此文件加载,后面的学习需要对此文件修改,所以可以先备份一下;现在启动Redis是前台启动的形式,启动后窗口不能执行其他操作,可以改为后台进行。
- 在opt目录下
makedir myconf创建myconf目录,将redis.conf复制到目录中。 - 修改myconf里面的配置文件,将daemonize no 改成 yes,让服务在后台启动。
再次执行redis-server /etc/opt/myconf/redis.conf。此时服务可以启动,执行redis-cli启动客户端,执行ping验证连通性,得到pong即为redis启动成功。

Redis启动杂项
Redis默认端口是6379,可以通过配置文件修改端口。
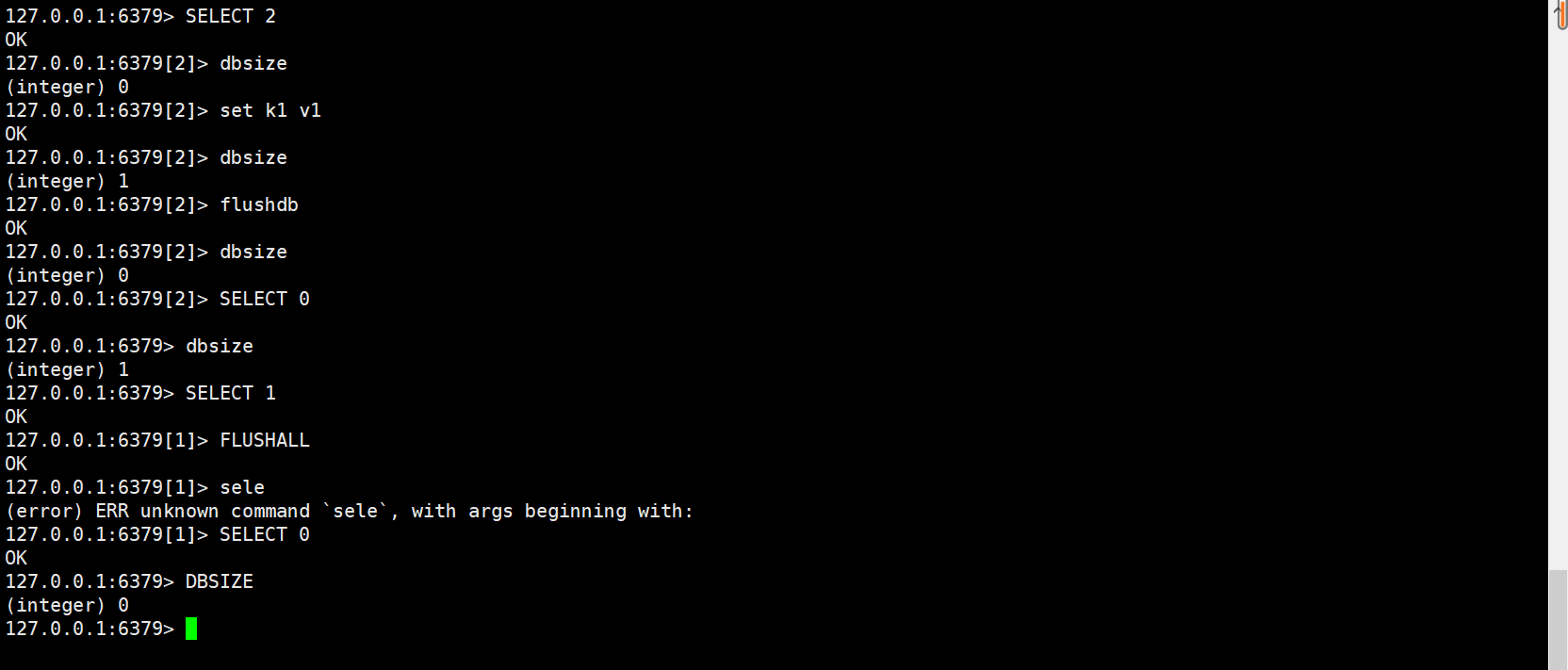
Redis默认数据库有16个

select命令切换数据库,默认使用0号库
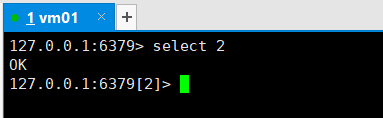
dbsize查看数据库的key数量
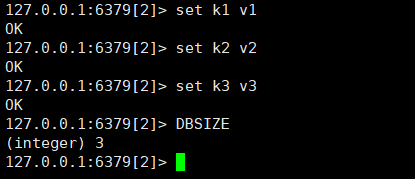
flushdb清空当前库、flushall清空所有库
统一密码管理:16个库都是用同样的密码
redis高效原因:单线程+多路复用技术
Redis单线程
Redis客户端对服务端的每次调用都经历了发送命令,执行命令,返回结果三个过程。其中执行命令阶段,由于Redis是单线程来处理命令的,所有每一条到达服务端的命令不会立刻执行,所有的命令都会进入一个队列中,然后逐个被执行。并且多个客户端发送的命令的执行顺序是不确定的。但是可以确定的是不会有两条命令被同时执行,不会产生并发问题,这就是Redis的单线程基本模型。
1.Redis不是完全单线程的
Redis单线程是处理网络请求使用单个线程来处理:即一个线程处理所有网络请求,其他模块仍使用多线程。
以Redis持久化为例,RDB方式持久化即为fork一个子线程将数据写入临时文件中。
2.Redis使用多路复用技术
Redis对读写时间的响应是通过封装epoll^epoll函数来实现的。Redis的实际处理速度完全依靠主进程的执行效率。

Redis数据结构
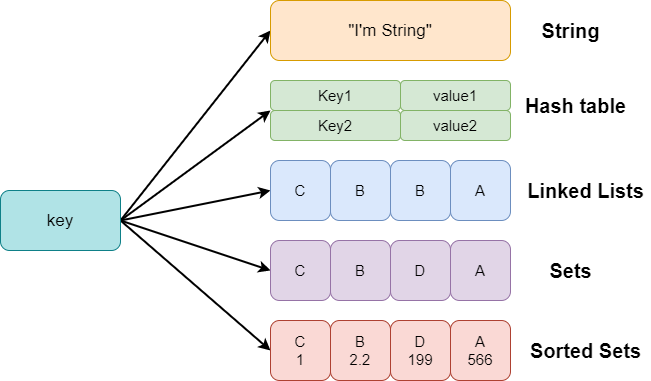
Redis的五大基本数据结构:
- 字符串String:字符串是Redis最基本的类型,采用key-value形式。一个redis中字符串value最大为512M;
- 哈希Hash:hash是一个键值对集合,是一个string类型的field和value的映射表;
- 列表List:list是一个字符串列表,按照插入顺序排序。他的底层实现是链表;
- 集合Set:set是一个string类型的无序集合,通过HashTable实现;
- 有序集合Zset(Sorted set):zset和set都是string类型的集合,不过zset中每个元素都会关联一个double类型的分数,redis通过这个分数危机和中的元素进行排序(zset的数据是唯一的,不过分数可以重复)
有关Redis的常见数据类型操作指令,可以在Redis命令参考中查看。
Redis Key
1.结构
对Redis来说,所有的Key都是字符串
2.常用指令
| 命令 | 描述 | 使用 |
|---|---|---|
| keys | 查看当前库的所有key | keys * |
| exist | 判断某个key是否存在 | exist key |
| type | 查看key的类型 | type key |
| del | 删除指定key的数据 | del key |
| unlink | 根据value选择非阻塞删除 | unlink key |
| expire | 未指定key设置过期时间 | expire key 10 |
| ttl | 查看还有多久过期 | ttl key |
执行结果如下:

1 | |
注:几个查看redis库的指令:
1 | |
Redis String
1.数据结构
String的数据结构为简单动态字符串(Simple Dynamic String,简写SDS)。是可修改的字符串,内部结构是线上类似于Java的ArrayList,采用预分配荣誉空间的方式来减少内少的频繁分配。

如图所示,内部为当前字符串实际分配的空间capacity,一般要高于实际字符串长度len。
当字符串长度小于1M,扩容方式是现有空间加倍;超过1M时,每次扩容只会增加1M空间。并且字符串的最大长度为512M
Redis的String类型是二进制安全的,意思是 redis 的 string 可以包含任何数据。如数字,字符串,jpg图片或者序列化的对象。
2.常用指令
| 命令 | 描述 | 使用 |
|---|---|---|
| SET | 设置指定key的value | set key1 value1 |
| GET | 获取指定key的value | get key1 |
| DEL | 删除指定的key-value | del key1 |
| INCR | 将对应key的value加1 | incr key1 |
| DECR | 将对应key的value减1 | decr key1 |
| INCRBY | 将对应key的value加指定整数 | incrby key1 count |
| DECRBY | 将对应key的value减指定整数 | decrby key1 count |
对string操作的指令执行结果如下(set、get、del上面已经演示):
1 | |

3.使用场景
- 缓存:最经典最常用的场景。将一些常用的信息放在redis中,redis作为缓存层,MySQL作为持久层,达到降低MySQL的读写压力。
- 计数器:Redis的单线程模型保证了他一次只会执行一个命令的特点
- session:采用Spring Session+Redis实现Session共享,一次登录多次使用。
Redis List
1.数据结构
List就是链表,Redis的List采用双端链表来实现,value可重复,类似于Java中的LinkedList。所以它的特性和链表相似:对两端的插入删除操作性能很好,但是通过索引定位查找的性能较差。
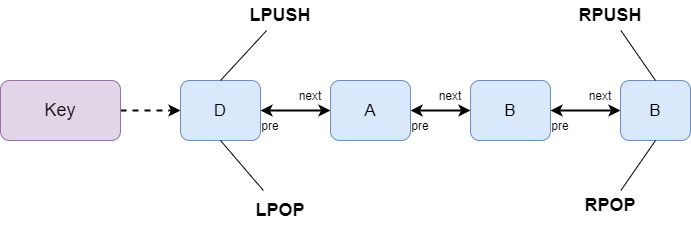
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。
当数据量比较多的时候才会改成quicklist。因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如一个列表里存储的是基本的int或string类型数据,结构上还需要两个额外的指针prev和next。
2.常用命令
list的使用命令如下:
1 | |
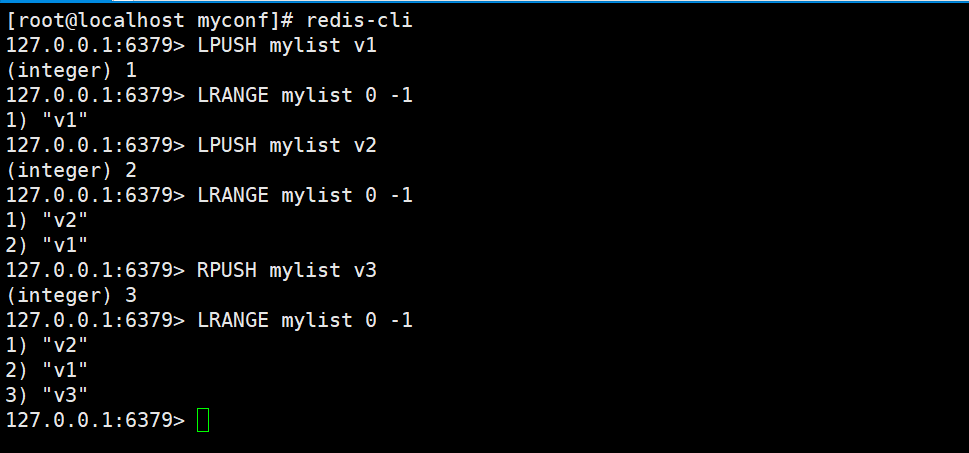
使用基础的LPUSH、RPUSH效果如图:
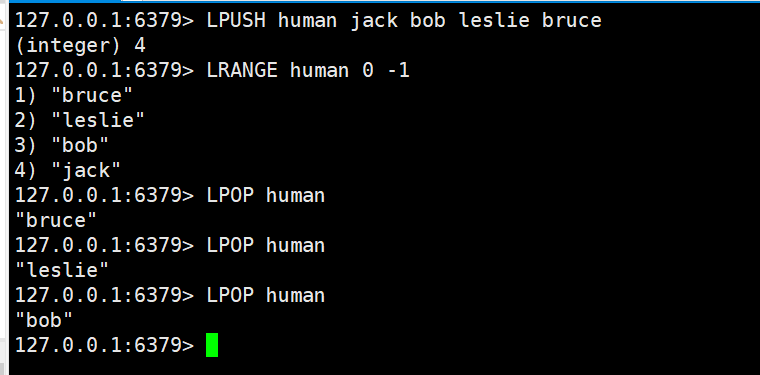
可以利用list的链表本质实现一些基本数据结构。
- list实现队列:LPUSH+RPOP或RPUSH+LPOP;利用队列先进先出的特点,实现消息队列或异步处理等操作。
- 2.list实现栈:LPUSH+LPOP或RPUSH+RPOP;实现了栈先进后出的特点。
3.使用场景
list常见的场景有消息队列、时间轴、点赞评论的列表等
Redis Hash
Redis的Hash字典是一个kv键值对集合,同时v也是一个string类型的field-value映射表。
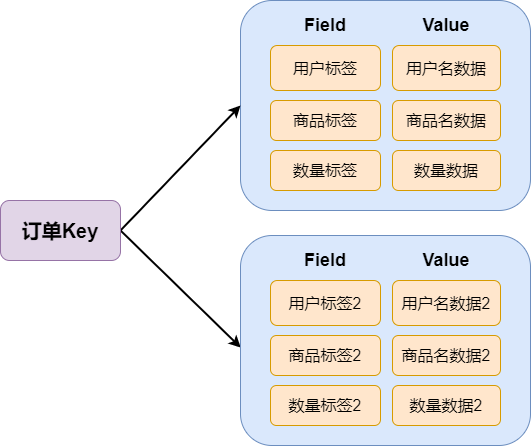
1.数据结构
Redis Hash类似于Java中的HashMap<String,Object>,内部实现上都是“数组+链表”的链地址法解决哈希冲突。
hash类型对应的数据结构是两种:ziplist(压缩链表)、hashtable(哈希表);当field-value长度较短且个数较少时使用ziplist,否则使用hashtable
2.常用命令
hash的常用指令如下:
1 | |
使用效果如图:
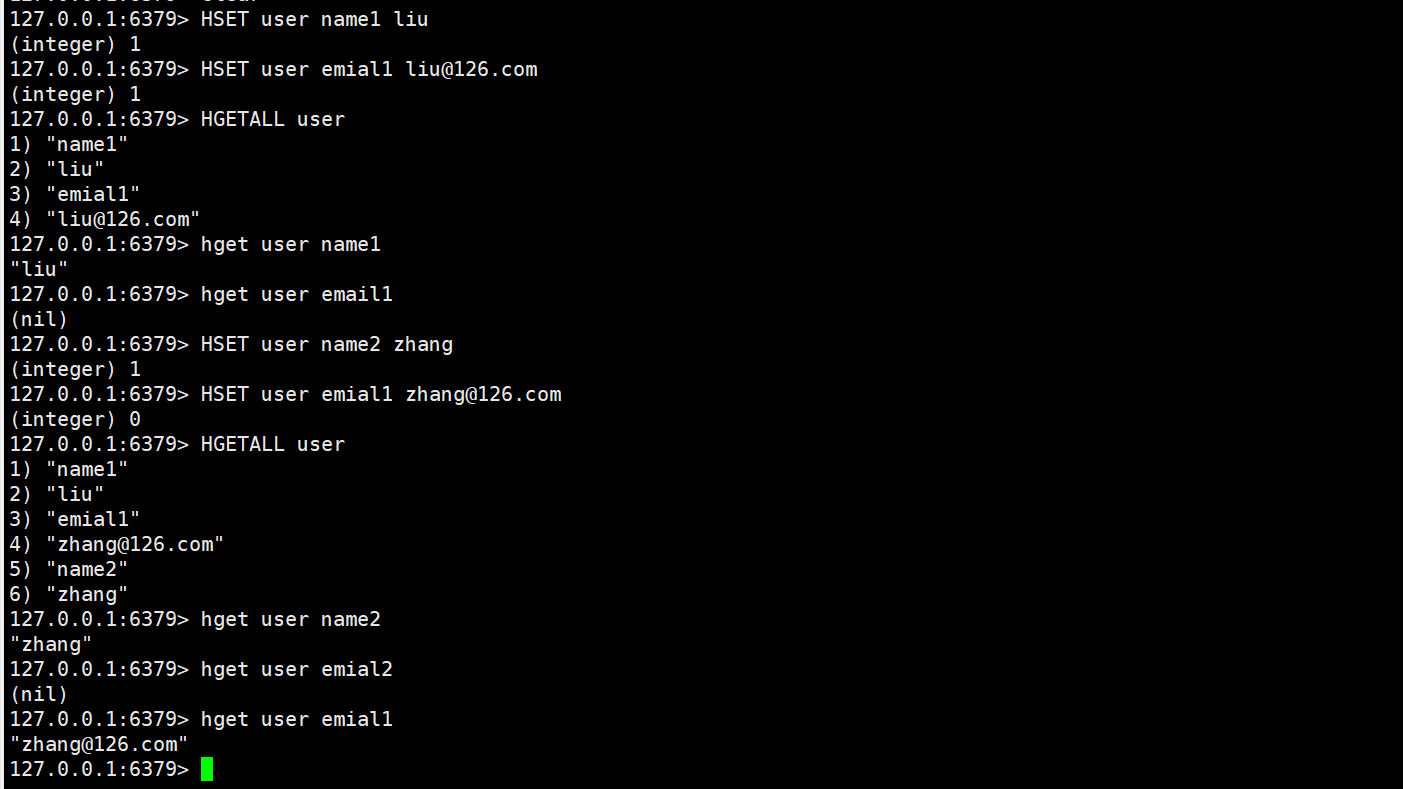
3.使用场景
更丰富的缓存:相比string存储字符串,hash可以存储object,可以用来存储用户信息、订单信息等
Redis Set
Set和List都是单key多value,不过set里面的value不允许重复;集合中的元素是无序的,不能通过下表获取元素;set可以利用集合特性实现相关操作,如取交集、并集等。Redis Set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
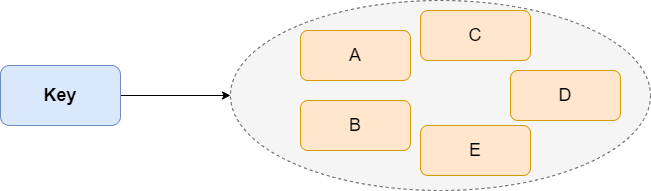
1.数据结构
Redis的Set是string类型的无序集合(dict字典)。它底层其实是一个value为null的hash表,所以添加,删除,查找的**复杂度都是O(1)**。
Java中HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
2.常用命令
Set的常用命令如下:
1 | |
使用效果如图:
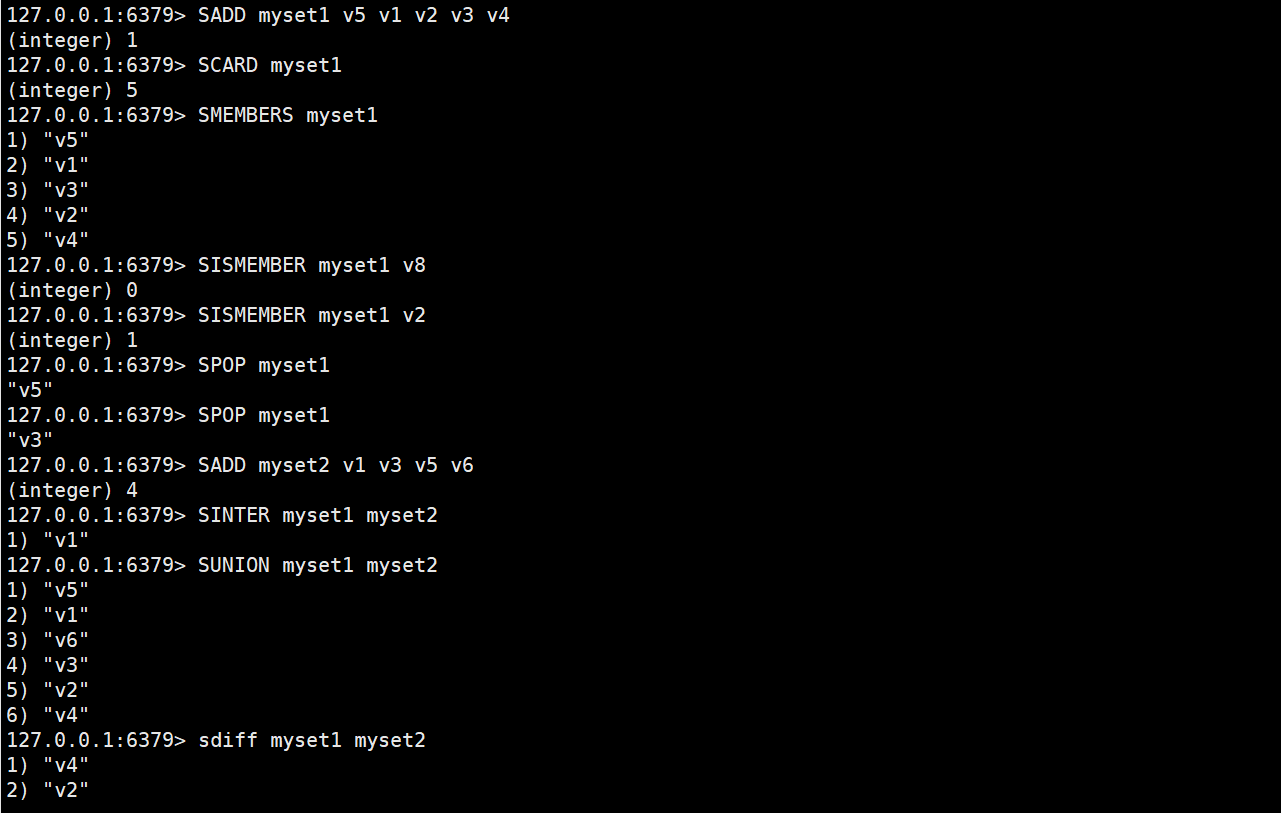
3.使用场景
- 标签(tag):给用户添加标签,或者用户给消息添加标签,这样有同一标签或者类似标签的可以给推荐关注的事或者关注的人。
- 点赞,或点踩,收藏等,可以放到set中实现。
Redis Zset
Zset在Set的基础上,为每个成员增加了一个评分score,通过按score由低到高给集合中的元素排序。集合中成员是唯一的,而score是可以重复的。
由于元素有序,所以可以根据评分score和次序position来快速获取一个区间的元素。
1.数据结构
SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构Map<String, Double>,可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部的元素会按照权重score进行排序,可以得到每个元素的名次,还可以通过score的范围来获取元素的列表。
zset底层使用了两个数据结构:
- hash,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。
- 跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。
2.常用命令
Zset常用命令如下:
1 | |
使用效果如图:
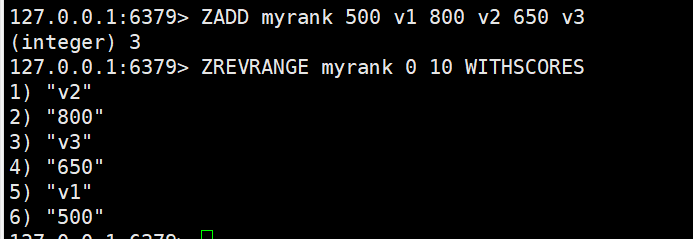
3.使用场景
比较常用的就是排行榜。比如文章阅读量热榜、商品销量热榜等实现。